A Sequence-to-Sequence model is a type of neural network architecture specifically designed for tasks involving sequential data. Seq2Seq models are the backbone of various applications, making them incredibly important in the field of artificial intelligence.
At the heart of Seq2Seq models are two essential components: the encoder and the decoder. The encoder processes the input sequence and encodes it into a fixed-length context vector. This context vector is a numerical representation of the input sentence’s meaning.
The decoder translates the context vector into the desired output sequence, be it another language or a response to a question. The decoder generates the output sequence one step at a time, taking into account the context vector and the previously generated words. This dynamic duo, the encoder-decoder pair, forms the foundation of Seq2Seq models.
Seq2Seq models have found their way into numerous real-world applications, enhancing our daily experiences in ways we might not even realize. Machine translation services, like Google Translate, utilize Seq2Seq models to provide accurate translations between languages. Chatbots, social media, and customer service platforms, also rely heavily on Seq2Seq architectures. By understanding the context of your queries, chatbots generate responses that seem natural and human-like.
They are trained on vast datasets containing pairs of input sequences and their corresponding output sequences. During training, the model learns to map input sequences to output sequences by adjusting its internal parameters through a process called backpropagation. This iterative learning process allows Seq2Seq models to improve their performance over time, becoming more accurate and reliable.
Traditional Seq2Seq models struggle when faced with lengthy input or output sequences due to vanishing gradient problems. Researchers have addressed this challenge through innovations like attention mechanisms, enabling the model to focus on specific parts of the input sequence when generating the output. This breakthrough significantly improves the accuracy and efficiency of Seq2Seq models, making them more versatile and capable.
In our case, it’s about converting human language into machine-understandable data and vice versa.
Setting Up Your Environment
Ensure you have Python installed on your system. If not, a quick visit to the Python website and following their installation instructions will do the trick.
You’ll need necessary libraries like TensorFlow and Keras. These libraries provide the tools and frameworks necessary for building Seq2Seq models effortlessly. Installation is a breeze; a simple command in your terminal or command prompt will do the job:
![]()
Gather a high-quality dataset. The effectiveness of your Seq2Seq model heavily depends on the quality of your data. You can find various datasets online, each tailored for specific applications, whether it’s language translation, chatbot development, or something else entirely. Websites like Kaggle and academic repositories are dood resorses for datasets.
Tokenization, the process of breaking down sentences into smaller units like words or subwords, is vital. Python libraries like Tokenizer from Keras simplify this process. Clean, well-preprocessed data ensures your model learns effectively and generates accurate results.
While basic Seq2Seq models can run on standard computers, training larger models or dealing with extensive datasets might require more computational horsepower. Consider utilizing cloud-based services like Google Colab, which provide free access to powerful GPUs, enabling you to train your models faster and more efficiently.
Consider employing version control systems like Git. They act as a safety net, allowing you to track changes, collaborate seamlessly, and revert to previous versions if needed. Platforms like GitHub offer a user-friendly interface, making collaborative coding a breeze.
Data Collection and Preprocessing
Start by identifying the purpose of your model. Once you have a clear goal, look for datasets specifically curated for that purpose.
Raw data, though abundant, is akin to scattered puzzle pieces. Preprocessing is where you meticulously organize and shape these pieces into a coherent picture. Tokenization, a fundamental preprocessing step, involves breaking down sentences into words or subwords. This process provides structure to the data, making it understandable to the machine.
Keras offers a handy tool called Tokenizer. It simplifies the tokenization process, converting text into numerical sequences, which the Seq2Seq model can comprehend. Here’s how you can use it:
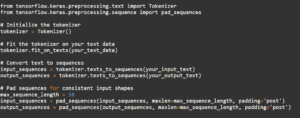
Building the Seq2Seq Model
In Keras, you can construct our Seq2Seq using the LSTM (Long Short-Term Memory) layers. LSTM networks are excellent choices for sequence prediction problems due to their ability to maintain context over long sequences.
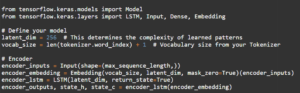
We have the decoder, your AI storyteller. It takes the encoded information and translates it back into the language humans understand. LSTM layers work here.

It’s time to unite the encoder and decoder, creating a harmonious conversation between them. This is where Keras truly shines, allowing you to effortlessly connect the layers.

Testing Your Chatbot
Interact with your chatbot, throw in different questions, and see how well it responds. Keep refining your model based on user interactions and feedback.
To truly gauge the capabilities of your chatbot, test it with a variety of scenarios. Introduce it to different conversational contexts, from casual chitchat to complex inquiries. By exposing your chatbot to diverse inputs, you can assess how well it adapts to the intricacies of human language.
What matters is how it handles errors? When faced with queries it doesn’t understand, does it seek clarification? Does it provide helpful suggestions? Error handling is an opportunity for your chatbot to learn and improve.
Encourage users to share their experiences and suggestions. Analyze this feedback meticulously. What do users like? Where do they find challenges? By listening to your users, you gain invaluable insights that drive iterative enhancements. This iterative process is what transforms a good chatbot into an exceptional one.
The testing phase is not a final destination but a checkpoint in your chatbot’s way. As you gather insights and feedback, use this information to continuously refine your chatbot. AI is about learning and adapting. With each interaction, your chatbot becomes smarter and more attuned to user needs.