If you’re learning and working with Keras, you’re familiar with the importance of fine-tuning your models to achieve the best results. One powerful tool at your disposal for this purpose is callbacks. Callbacks in Keras are essential for monitoring and controlling the training process, allowing you to adapt and optimize your neural network as it learns from data.
In the context of Keras and deep learning, a callback is a set of functions that can be applied at different stages during the training of a neural network. These functions are called at predefined points during training, such as at the end of each epoch or after a batch of data has been processed. Some common use cases of callbacks include:
Model Checkpointing
It allows you to save the weights of your model at specific intervals during training. These weights represent the essence of what your neural network has learned so far. By saving them, you create checkpoints in your training process. Should an unfortunate event occur, like a system hiccup, you can seamlessly pick up where you left off, instead of starting from scratch. It offers you fine-grained control over what you save and when you save it. You can specify:
Choose a meaningful name for your checkpoint file, making it easy to identify later.
Decide which metric you want to monitor for the best model. Common choices include validation loss or accuracy.
You can opt to save only the weights of the model when it performs better than the previous best. This prevents your storage from being cluttered with suboptimal checkpoints.
If you’re tight on storage, you can choose to save only the model’s weights, not the entire architecture. This saves space without sacrificing functionality.
Early Stopping
It stops the training process early, long before it devolves into overfitting territory. Early Stopping relies on a separate set of data called validation data. While your model trains on the training data, it continually evaluates its performance on the validation data.
Early Stopping allows you to set a ‘patience’ parameter. This is like telling it to be patient, to wait and see if things get better. If the performance doesn’t improve for a defined number of epochs, it intervenes and stops the training.
It not only helps you avoid overfitting but also saves precious time and computational resources. Instead of training your model for a fixed number of epochs, you let it train until it’s no longer learning effectively. This is a more efficient way to achieve the best results, especially when you’re working with vast datasets and complex models.
Learning Rate Adjustment
A proper learning rate is essential. Too high, and the model may overshoot the optimal solution, too low, and the training might be excessively slow. Instead of sticking with a fixed rate, which might not suit every phase of training, this technique allows you to change the learning rate as needed.
As it approaches the optimal solution, smaller learning rate steps become crucial for precise convergence. Static learning rates might be too large, causing the model to overshoot and miss the mark. Dynamic learning rates adapt to these changing conditions, ensuring a more controlled and efficient path to convergence.
Custom Logging
While training a neural network, you typically monitor standard metrics like loss and accuracy. However, your project might demand more specialized metrics or insights specific to your problem. Custom Logging allows you to collect and log this unique information.
With Custom Logging, you can capture a wide range of data during training:
Track any metric relevant to your problem, whether it’s a unique performance measure or an auxiliary statistic crucial for analysis.
Log intermediate outputs of layers in your network. This can help you understand how the model processes data at different stages.
Save visualizations of data, such as feature maps, activation maps, or images, to gain insights into the network’s behavior.
Record the values of hyperparameters used during training, aiding in future experimentation.
Keep a detailed log of training progress, including epoch-by-epoch statistics and any significant events that occur.
Visual representations of data can be incredibly insightful. You can create plots, graphs, and charts to gain a more profound understanding of your model’s performance.
Data Augmentation
It is creating new training examples by applying various transformations to your existing data. These transformations are carefully chosen to preserve the essential characteristics of the data while introducing variability. Here’s why it’s essential:
By exposing your model to a more extensive range of data variations, it becomes more robust and better at handling unseen data.
Data Augmentation can help prevent your model from memorizing the training data (overfitting) by introducing diversity.
You can maximize the potential of your dataset, especially when you have limited samples.
TensorBoard Integration
TensorBoard is a web-based tool provided by TensorFlow, a popular deep-learning framework. It’s designed to work seamlessly with your deep learning models, offering a range of visualizations and metrics to help you monitor, troubleshoot, and optimize your neural networks.
It provides real-time graphs of critical training metrics like loss and accuracy. Watching these metrics evolve over time can give you immediate feedback on your model’s performance.
You can visualize the structure of your neural network, making it easier to understand how data flows through the various layers.
TensorBoard allows you to track the distribution of weights and biases in your model. This insight is invaluable for debugging and fine-tuning.
For tasks like dimensionality reduction or visualization of embeddings (e.g., word embeddings in NLP), TensorBoard provides interactive visualizations to explore the learned representations.
You can create custom plots and visualizations tailored to your specific needs, helping you gain deeper insights into your data and model behavior.
Implementing Callbacks in Keras
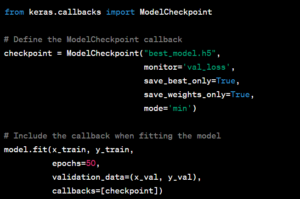
To save the model’s weights during training, you can use the ModelCheckpoint callback provided by Keras. By specifying parameters such as the filename and monitoring metric, you can save the best model weights automatically. Here’s a simple example:
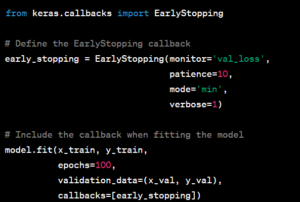
To prevent your model from overfitting and save training time, you can implement early stopping with the EarlyStopping callback. This callback monitors a specified metric (usually validation loss) and stops training if the metric stops improving. Here’s how to use it:
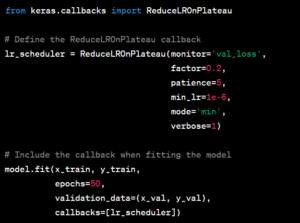
Dynamic learning rate adjustments can improve training stability. You can use the ReduceLROnPlateau callback to reduce the learning rate when a monitored metric (e.g., validation loss) plateaus. Here’s an example: